GPU之后,AI算力加速找到新方向

种种迹象表明,得益于自身对神经网络计算进行的专门优化,在端侧和边缘侧处理复杂神经网络算法时拥有的更高效率和更低能耗,神经网络处理器(NPU)正成为推动AI手机、AI PC和端侧AI市场前行的强大动能,并有望开启属于自己的大规模商用时代。
什么是NPU?
NPU是一种专为实现以低功耗加速AI推理而打造的处理器,其架构随着新AI算法、模型和用例的发展不断演进。一个优秀的、专用的定制化NPU设计必须要在性能、工号、效率、可编程性和面积之间进行权衡取舍,才能够为处理AI工作负载做出正确的选择,与AI行业方向保持高度一致。3OHesmc
早在2015年,面向音频和语音AI用例而设计的NPU就诞生了,这些用例基于简单卷积神经网络(CNN)并且主要需要标量和向量数学运算。从2016年开始,拍照和视频AI用例大受欢迎,出现了基于Transformer、循环神经网络(RNN)、长短期记忆网络(LSTM)和更高维度的卷积神经网络(CNN)等更复杂的全新模型。这些工作负载需要大量张量数学运算,因此NPU增加了张量加速器和卷积加速,让处理效率大幅提升。3OHesmc
到了2023年,大语言模型(LLM)一比如Llama 2-7B,和大视觉模型(LVM)一比如 StableDiffusion赋能的生成式AI使得典型模型的大小提升超过了一个数量级。除计算需求之外,还需要重点考虑内存和系统设计,通过减少内存数据传输以提高性能和能效。未来预计将会出现对更大规模模型和多模态模型的需求。3OHesmc
AI PC将NPU推上竞争新高地
2024年被普遍视为AI PC元年,根据Canalys预测,到2027年,AI PC出货量将超过1.7亿台,其中近60%将部署在商用领域。为了顺应PC行业的发展潮流,并显著提高端侧AI能力,英特尔、AMD、高通等头部芯片厂商也正努力将专用NPU集成到CPU中,相关产品及路线图已经得到公布。3OHesmc
尽管AI PC实际市场表现取决于生态系统的协作水平,但毫无疑问的是,集成了NPU的中央处理器将驱动新一轮AI PC的发展。与此同时,如何在电脑处理器中发挥出NPU的最大功效,也成为了业内热议的话题。3OHesmc
2023年12月,AMD率先发布锐龙8040系列处理器,其最核心的变化之一就是新增了AI计算单元。根据AMD的说法,得益于NPU的加入,锐龙8040系列处理器的AI算力从10TOPS提升到了16TOPS,性能提升幅度达到了60%。这让锐龙8040系列处理器在LLM等模型性能更加突出,例如Llama 2大语言模型性能提升40%,视觉模型提升40%。3OHesmc
一周之后,英特尔新一代酷睿Ultra移动处理器正式发布,这是其40年来第一个内建NPU的处理器,用于在PC上带来高能效的AI加速和本地推理体验,被业界视作英特尔客户端处理器路线图的转折点。英特尔方面将NPU与CPU、GPU共同作为AI PC的三个底层算力引擎,预计在2024年,将有230多款机型搭载酷睿Ultra。3OHesmc
 3OHesmc
3OHesmc
来自Trendforce的消息称,微软计划在Windows12中为AI PC设置最低门槛,需要至少40TOPS算力和16GB内存。也就是说,PC芯片算力跨越40TOPS门槛将成为首要目标,这也将进一步推进NPU的升级方向,比如:提升算力、提高内存、降低功耗,芯片持续进行架构优化、异构计算优化和内存升级。3OHesmc
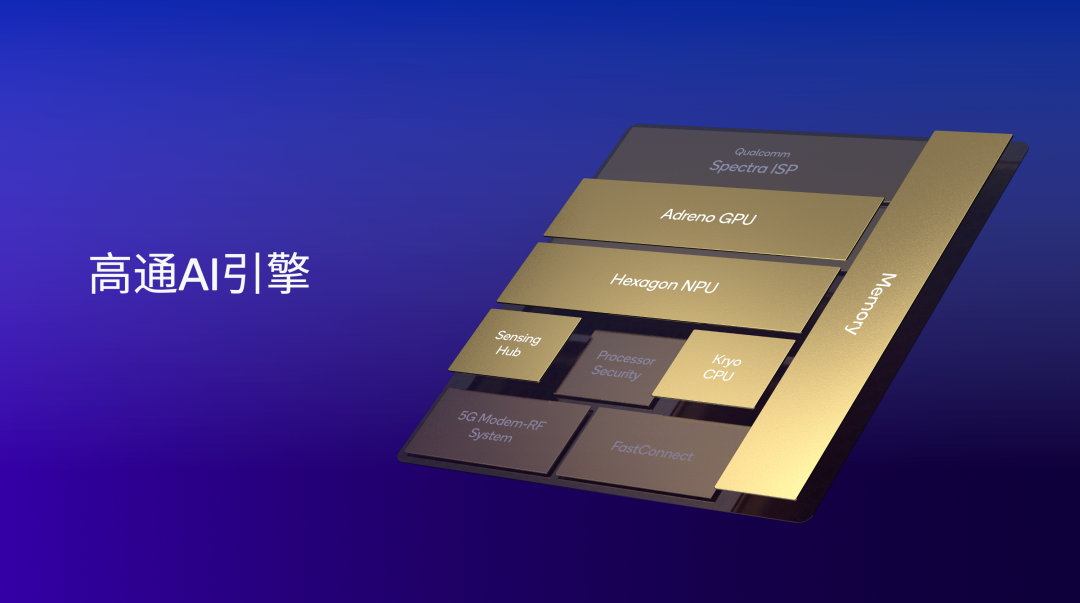
再来看一下高通的思路。高通是不打算从一开始就只依赖NPU实现移动设备AI体验的,而是将Hexagon NPU、Adreno GPU、Kryo或Oryon CPU、传感器中枢和内存子系统“打包”,组成“高通AI引擎”。这意味着高通NPU的差异化优势在于系统级解决方案、定制设计和快速创新。通过定制设计NPU并控制指令集架构(ISA),高通能够快速进行设计演进和扩展,以解决瓶颈问题并优化性能。目前,高通NPU从2015年初次被集成到SoC至今,在9年左右的时间里其实已经更迭了四代不同的基础架构。3OHesmc
 3OHesmc
3OHesmc
本土NPU企业持续发力
在国内厂商当中,2017年,华为最先将NPU处理器集成到手机CPU中,使得CPU单位时间计算的数据量和单位功耗下的AI算力得到显著提升,让业内看到了NPU应用于终端设备的潜力。OPPO曾经的自研NPU马里亚纳X,在拍照、拍视频等大数据流场景下实现了更好的运算效率,拉开了高端智能手机的体验差距。3OHesmc
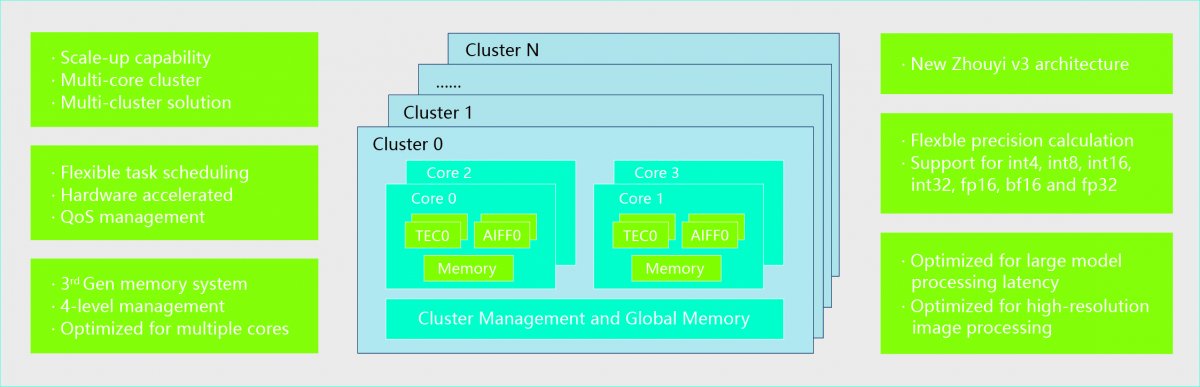
2018年11月,作为安谋科技成立后第一款正式对外发布的本土研发IP产品,“周易”Z1 NPU在乌镇举办的第五届世界互联网大会上公开亮相;两年后的2020年10月,能够在单颗SoC中实现128TOPS强大算力的“周易”Z2 NPU面世;2023年推出的“周易”X2 NPU则主要面向智能汽车产业和边缘计算,支持多核Cluster,以及大模型基础架构Transformer,可提供最高320TOPS的算力。商业化落地方面,目前“周易”NPU已和全志科技、芯擎科技、芯驰科技等多家本土芯片厂商实现了合作。3OHesmc
 3OHesmc
3OHesmc
“周易”X2 NPU主要功能升级(来源:安谋科技)3OHesmc
另一家企业芯原则在近日宣布,集成其NPU IP的AI芯片在全球范围内出货超过1亿颗,已被72家客户用于128款AI芯片中,用于物联网、可穿戴设备、智慧家居、安防监控、汽车电子等10个市场领域。其最新推出的VIP9000系列NPU IP结合芯原的Acuity工具包支持含PyTorch、ONNX和TensorFlow在内的所有主流框架。此外,它还具备4位量化和压缩技术,以解决带宽限制问题,便于在嵌入式设备上部署生成式人工智能和大型语言模型算法,如Stable Diffusion和Llama 2。3OHesmc
作为人工智能视觉感知芯片研发及基础算力平台公司,爱芯元智在2023年正式推出的第三代高算力、高能效比的SoC芯片AX650N,也为行业探索Transformer在端侧、边缘侧落地方面做出了有益的尝试。实测数据显示,目前大众普遍采用的Transformer网络SwinT,在爱芯元智AX650N平台上获得了361 FPS的高性能、80.45%的高精度、199FPS/W的低功耗以及原版模型且PTQ量化的极易部署能力。3OHesmc
生成式AI与多样化处理器
与我们之前谈论的AI不同的是,生成式AI用例需求在有着多样化要求和计算需求的垂直领域不断增加。高通在《通过NPU和异构计算开启终端侧生成式AI》的白皮书中,将这些用例分为三类:3OHesmc
1. 按需型用例由用户触发,需要立即响应,包括照片/视频拍摄、图像生成/编辑、代码生成、录音转录/摘要和文本(电子邮件、文档等)创作/摘要。这包括用户用手机输入文字创作自定义图像、在PC上生成会议摘要,或在开车时用语音查询最近的加油站。3OHesmc
2. 持续型用例运行时间较长,包括语音识别、游戏和视频的超级分辨率、视频通话的音频/视频处理以及实时翻译。这包括用户在海外出差时使用手机作为实时对话翻译器,以及在PC上玩游戏时逐帧运行超级分辨率。3OHesmc
3. 泛在型用例在后台持续运行,包括始终开启的预测性AI助手、基于情境感知的AI 个性化和高级文本自动填充。例如手机可以根据用户的对话内容自动建议与同事的会议、PC端的学习辅导助手则能够根据用户的答题情况实时调整学习资料。3OHesmc
白皮书指出,这些AI用例面临两大共同的关键挑战:第一,在功耗和散热受限的终端上使用通用CPU和GPU服务平台的不同需求,难以满足这些AI用例严苛且多样化的计算需求;第二,这些AI用例在不断演进,在功能完全固定的硬件上部署这些用例不切实际。3OHesmc
例如CPU和GPU是通用处理器,它们为灵活性而设计,非常易于编程,前者擅长顺序控制和即时性,后者适合并行数据流处理。但在运行操作系统、游戏和其他应用时,会随时限制他们运行AI工作负载的可用容量;NPU是以AI为中心定制设计的,擅长标量、向量和张量数学运算,虽然易编程性有所降低,但以此换得了更高的峰值性能、能效和面积效率,从而能够运行机器学习所需的大量乘法、加法和其他运算。3OHesmc
因此,只有支持处理多样性的异构计算架构,才能够发挥每个处理器的优势。正如在工具箱中选择合适的工具一样,选择合适的处理器取决于诸多因素,将增强生成式AI体验。换句话说,就是通过使用合适的处理器,异构计算能够实现最佳应用性能、能效和电池续航,以最大化发挥生成式AI终端用户体验。3OHesmc
端侧AI,千帆竞渡
如前文所述,无论是国际还是国内企业,尽管他们在NPU的技术和路线选择上各有侧重,但端侧AI是显而易见的竞争大市场和新市场,无论是AI手机、XR、AI PC等消费类产品,还是物联网、智慧家居、汽车电子领域,都是如此。3OHesmc
究其原因,还是自2023年起,大模型参数量出现显著分化,轻量化模型的出现逐步推动AI向端侧场景落地。以谷歌发布的开源轻量化大模型Gemma为例,该模型与多模态大模型Gemini采用相同的研究和技术构建,有2B和7B两个版本,可以直接在笔记本和台式机部署。 3OHesmc
近几年大有取代CNN之势的Transformer也值得多说几句。由于它可以获取全局特征,有一定的知识迁移性,能够很好地适应各种场景,不仅在COCO榜单上处于霸榜状态,很多以CNN为主的框架也已经切换到了Transformer。目前来看,Transformer大模型在云端主要还是通过GPU部署,在边缘侧、端侧硬件支撑方面,则更多依赖NPU实现对神经网络的加速。3OHesmc
这倒不是指CPU不能运行Transformer模型,只是它的运行速度无法满足实际应用落地需求。另一方面,尽管CNN和Transformer都属于神经网络,但Transformer的计算访存比比CNN低,精度和灵活度高,而此前市面上的一些NPU主要针对CNN网络做了一些过拟合的设计,导致在部署Transformer网络时遇到了功耗、效率等诸多问题,现在需要找到合适的新算力平台,并在算法侧找到能降低大参数模型带宽的新途径。3OHesmc
此外,轻量化AI大模型面世之后,场景应用的AI智能边际成本会大幅降低,因为它不太需要再为这些长尾的场景做专门的适配,预训练的大模型凭借“足够强的学习和推理能力”、“足够宽的知识领域”,一经部署就能达到比较好的效果,从而推动AI在端侧和边缘侧更大范围内的普及和提升。3OHesmc
结语
多模态AI的兴起,使得AI系统能够更全面地理解和处理现实世界中的复杂信息。除传统的语言以及图像间的交互作用,其结合声音、触觉以及动作等多维度信息进行深度学习,从而形成更准确、更具表现力的多模态表示。这也是AI模型走向多模态的必然因素:跨模态任务需求+跨模态数据融合+对人类认知能力的模拟。因此,端侧AI越“卷”,越代表着NPU将快速迎来市场拐点。3OHesmc
得益于在端侧和边缘侧处理复杂神经网络算法时拥有的更高效率和更低能耗,神经网络处理器(NPU)正成为推动AI手机、AI PC和端侧AI市场前行的强大动能,并有望开启属于自己的大规模商用时代。3月28-29日,由Aspencore举办的国际集成电路展览会暨研讨会(IIC Shanghai)将在上海召开。在与IIC 2024同期举办的“GPU/AI芯片与高性能计算应用论坛”上,行业专家将与我们共同探讨AI产业的最新动向及技术趋势,点击这里参考详情并报名参会。3OHesmc
 3OHesmc
3OHesmc

-
微信扫一扫,一键转发
-

关注“国际电子商情” 微信公众号
- 英特尔已暂停法国、意大利芯片投资计划
国际电子商情23日讯 据外媒报道,芯片制造业务面临巨额亏损,迫使英特尔暂停在法国和意大利的芯片厂投资计划。
- 大芯片病,怎么治?
2020年10月,英伟达将基于Mellanox的智能网卡(SmartNIC)方案命名为数据处理单元(Data Processing Units, DPU),并将CPU、GPU、DPU称之为组成“未来计算的三大支柱”。
- 软银宣布收购英国AI芯片公司Graphcore
国际电子商情12日讯 日本软银集团以未公开的金额收购了人工智能芯片制造商 Graphcore,结束了人们对该公司未来的长期猜测。
- 应对半导体制造用工荒,美国再推“劳动力伙伴联盟”计划
国际电子商情2日讯 据外媒报道,美国拜登政府正在启动一项培养美国计算机芯片劳动力的计划。
- 欧盟能靠投资RISC-V实现芯片自主吗?
欧盟大力投资以RISC-V开源架构实现芯片独立的倡议。这项工作由巴塞罗那超级计算中心牵头,该中心在RISC-V技术的开发方面一直走在前列。
- 芯片巨头Intel遭遇集体诉讼:涉嫌隐瞒代工业务巨额亏损
国际电子商情17日讯 据外媒报道,芯片巨头英特尔公司目前正面临一场集体诉讼。原告方指控英特尔在2023年的业绩报告中未正确披露其晶圆代工部门的巨额亏损情况。
- 消息称英特尔暂停以色列250亿美元工厂扩建计划
国际电子商情12日讯 美国芯片制造商英特尔公司已决定停止在以色列扩建其价值250亿美元的芯片工厂,也通知供应商取消了为新工厂提供设备和材料的合同。
- PC市场开始反弹:Arm攻势猛烈,英伟达可能要造CPU...
要观察消费电子市场的兴衰,最该在意的无疑一是手机,一是PC。过去一季常听行业谈起市场要恢复,这个话题有没有说服力,主要就看手机和PC市场有没有恢复了。
- 2024,MCU的“四大变局”
随着物联网设备的快速增长和智能化水平的提高,微控制器(MCU)作为智能设备的核心部件,正面临着前所未有的发展机遇。
- 借瑞萨RA8系列MCU,聊聊Arm Helium技术
我们一直都很好奇,MCU作为一种对实时性有要求的控制器,是如何实现边缘AI处理工作的。所以这篇文章,我们期望借着RA8来谈谈Arm Helium技术。
- 传软银洽谈收购英国AI芯片公司Graphcore
国际电子商情11日讯 近日,有消息称,日本软银或在洽谈收购英国芯片设计公司Graphcore…
- iFixit拆解华为Pura 70称本土零部件价值高于Mate 60
国际电子商情9日讯 据拆解机构调查发现,华为 (Huawei) 最新发布手机配备更多的中国供应商组件,包括一款新的闪存芯片和一款改进的芯片处理器,这表明中国在技术自给自足方面正在取得进展。
- AI芯片供不应求,业界:半导体后端制程标准应统一
在各大半导体厂商抢攻AI商机之际,芯片产能却赶不上需求。
- 2024年全球AI服务器产值可望达1870亿美元,约占服务器市场比重65%
TrendForce集邦咨询预估AI服务器第2季出货量将季增近20%,全年出货量上修至167万台,年增率达41.5%。
- 预估2024年DRAM及NANDFlash营收将分别同增75%和77%
根据TrendForce集邦咨询最新存储器产业分析报告,受惠于位元需求成长、供需结构改善拉升价格,加上HBM(高带宽内
- 预计2025年存储器产业营收将创新高,价格上涨和HBM、QLC技术崛起为
根据TrendForce集邦咨询最新存储器产业分析报告,受惠于位元需求成长、供需结构改善拉升价格,加上HBM(高带宽内
- 中国团队存储器研究取得系列进展
近日,中国科学院上海微系统与信息技术研究所宋志棠、雷宇研究团队,在三维相变存储器(3D PCM)亚阈值读取电路、高
- TCL电子上半年MiniLED电视全球出货量同比增长122.4%
7月21日,TCL电子公布2024年上半年全球出货量数据,TCL电子表示,得益于公司在全球市场的积极开拓和品牌影响力的
- 厚度仅100nm!新型超薄晶体薄膜半导体被成功研制
据美国趣味科学网站16日报道,来自美国麻省理工学院、美国陆军作战能力发展司令部(DEVCOM)陆军研究实验室和加拿
- 车用及不可见光业务旺,亿光下半年业绩可望逐季成长
全球LED市场复苏,车用照明与显示、照明、LED显示屏及不可见光LED等市场需求有机会逐步回温,亿光下半年车用及
- 拆解:三星GalaxyWatch7中的ExynosW1000处理器3nmGAA工艺
三星最新推出的Galaxy Watch 7,继续重新定义可穿戴技术的极限。这款最新型号承袭了其前身产品的成功之处,同时
- 2024年Q2印度智能手机市场微增1%,小米重返榜首
2024年第二季度,在印度大选、季节性需求低迷以及部分地区极端天气等各种因素的影响下,印度智能手机市场微增1%
- 三星连续51个季度领跑拉丁美洲智能手机市场
根据TechInsights无线智能手机战略(WSS)的最新研究,2024年Q1,拉丁美洲智能手机出货量强劲增长,同比增长21%。
- 2030年,Chiplet计算细分市场规模预计将达到1450亿美元
Chiplet的出现标志着半导体设计和生产领域正在经历一场深刻的变革,尤其在设计成本持续攀升的背景下。
- 定档!IC CHINA 2024将于11月在北京举办!!
“芯”聚正当时!第二十一届中国国际半导体博览会(IC CHINA 2024)正式定档,将于2024年11月18-20日在北京·国家
- 国民技术将携多款高能专用MCU亮相全球MCU及嵌入式生态发展大会
7月25日,由全球领先的专业电子机构媒体AspenCore与深圳市新一代信息产业通信集群联合主办的【2024国际AIoT生
- 凯新达科技 ┃ 亮相2024中国(西部)电子信息博览会
2024年7月17日-19日,国内专业的电子元器件混合分销商凯新达科技(Kaxindakeji)应邀参加2024年中国(西部)电子信息
- 芯片产业链大咖齐聚苏州,共商供应链管理策略
在7月12日下午的“芯片分销及供应链管理研讨会”分论坛上,芯片分销及供应链专家共聚一堂,共谋行业发展大计。
- “芯”机遇 ! 凯新达科技亮相2024慕尼黑上海电子展
7月8日-10日,2024慕尼黑上海电子展(elec-tronica China)于上海新国际博览中心盛大开展,凯新达科技被邀重磅亮
- 未来可期——浙豪携手小华半导体亮相慕尼黑上海电子展
2024年7月8日到10日 ,浙豪半导体(杭州)有限公司作为小华半导体的优秀合作伙伴,在2024慕尼黑上海电子展上展出了
- 领芯微携LCM32F067系列MCU亮相国际AIoT生态发展大会
7月25日,由全球领先的专业电子机构媒体AspenCore与深圳市新一代信息产业通信集群联合主办的【2024国际AIoT生
- 2024 Matter 开发者大会7大看点不容错过!
近日,2024 Matter 中国区开发者大会在广州隆重召开。
- 泰凌微将携低功耗物联网无线芯片亮相国际AIoT生态发展大会
7月25日,由全球领先的专业电子机构媒体AspenCore与深圳市新一代信息产业通信集群联合主办的【2024国际AIoT生
- 第十六届集成电路封测产业链创新发展论坛在苏州开幕
7月13日,以“共筑先进封装新生态,引领路径创新大发展”为主题的第十六届集成电路封测产业链创新发展论坛(CIPA
- 摩尔斯微电子任命胡文杰为副总裁兼大中华区及东南亚地区经理
新任副总裁将推动亚太地区的增长和创新。
- 低碳化、数字化推动可持续发展,英飞凌亮相2024慕尼黑上海电子展
以碳化硅和氮化镓为代表的宽禁带半导体已成为绿色能源产业发展的重要推动力。